 |
||||||||||||||
|
||||||||||||||
|
|
||||||||||||||

 |
||
|
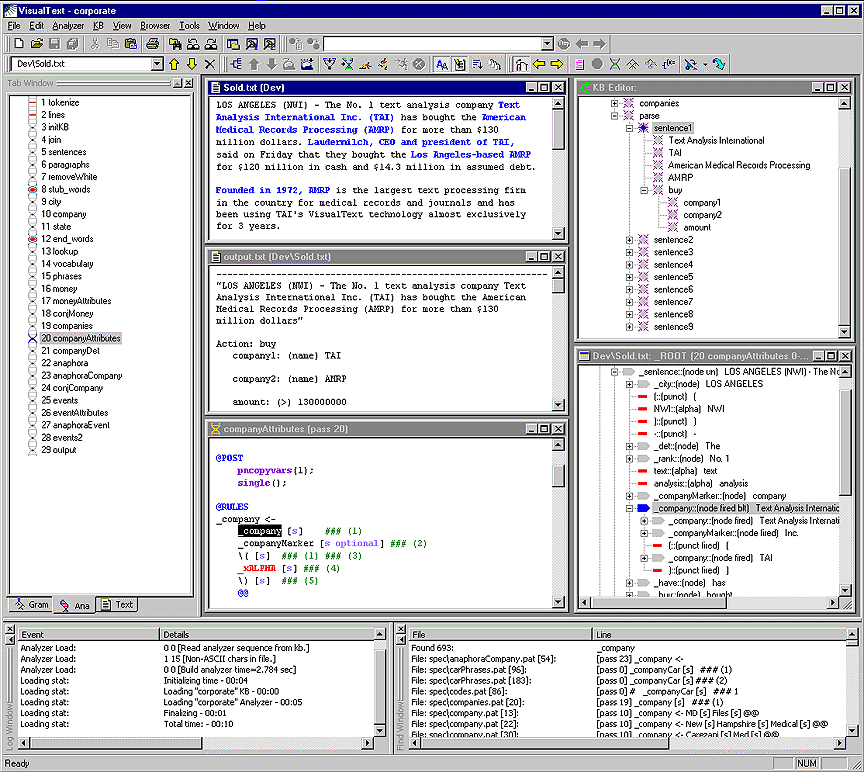
VISUALTEXT® VisualText is an ideal tool for quickly developing accurate and fast information extraction, natural language processing, and text analysis systems for the most complex needs. You can use the VisualText IDE (Integrated Development Environment) to automatically populate databases with the critical content now buried in textual documents. For example, you can extract business events from web news sites and create a searchable database for the latest business information. VisualText has been used to build a number of applications, including accurate analyzers for extracting information from resumes, systems that categorize web pages, an analyzer that monitors a financial transaction chat, email analyzers, selective web spiders, and more. A key discriminator of VisualText is that it enables you to build analyzers that can be maintained and enhanced by non-programmers and non-linguists. Simply by highlighting new phrases in a text, the user can generate an enhanced analyzer automatically. VisualText automatically generates new rules and layers them into the analyzer framework. Our analyzers are "glass box", letting you create and manage knowledge, grammar, and algorithms. You can build a text analyzer from beginning to end entirely within VisualText. By iteratively modifying and testing the analyzer without having to wait for code and rules to compile, you can develop text analyzers quickly and conveniently. We have proved this by building prototypes in a matter of days - sometimes hours! Download a screenshot of Visual Text here. TAI provides training for VisualText and offers professional services to help get your analyzers underway. TAIPARSE TAIParse is an advanced prototype for part-of-speech tagging, chunking, parsing, and more. It serves as a starting point for developing and tailoring of deep and accurate text analyzers. Further description and download is available here.
VisualText is a unique integrated development environment (IDE) for developing text analyzers. It tightly integrates our revolutionary NLP++® programming language for rapid analyzer building, Conceptual Grammar™ knowledge base management system for representing linguistic, conceptual, and domain knowledge, a rule generation system that learns from samples, and a runtime analyzer engine. Analyzers developed with VisualText can run stand-alone or embedded in larger applications on most computers that run C++ (e.g., Linux). The VisualText GUI development platform runs on PCs with Windows NT, Windows 2000, Win98, and WinME. Analyzers can run in interpreted mode, or get compiled to C++ libraries for faster execution. Knowledge bases associated with text analyzers can similarly be executed in interpreted mode or compiled to C++ libraries. TEXT ANALYZER APPLICATIONS Who needs a text analyzer? Anyone who needs to process documents, reports, web pages, email, chats, and any other communication. Voice processing is a very hot area, but once the voice is converted to text, something needs to process that text. We are all inundated with textual information. TAI's VisualText technology leads the way to more accurate and complete solutions to this universal challenge. Major application areas are web, business, law, medicine, military, and government. Visual Text is ideal for text analysis applications to combat terrorism, narcotics, espionage, and nuclear proliferation. Text from speech, email, and chat dialogues are other large application areas. Below is a sampling of application types that Visual Text can address: -Information Extraction - Systems that accurately extract, correlate, and standardize important information from text. For example, converting business articles to a structured business database. -Shallow Extraction - Systems that accurately identify names, locations, dates, and other atomic features of text. -Indexing - Indexing to support quality search capabilities on the World Wide Web and other electronic text sources. -Filtering - Systems that are both accurate and fast, to determine if a document is relevant. -Categorization - Systems to determine the topic of documents. -Data Mining - Finding important nuggets of information in voluminous texts. -Test Grading - Reading and matching prose tests with idealized answers. -Summarization - Building a brief, accurate description of the contents of a text. -Automatic Coding - E.g., resumé processing, medical reports, and police reports. -Natural Language Query - The ability to ask a computer questions using plain text. -Dissemination - Routing documents to people or locations that require them. Copyright © 1998-2013 Text Analysis International, Inc. All Rights Reserved |
||
 VISUALTEXT TECHNICAL FEATURES
VISUALTEXT TECHNICAL FEATURES
{kind=link}